AI crawler access is the new dimension of SEO and content strategy that publishers have to manage alongside the classic Googlebot relationship. As of 2026, the AI vendor crawlers (OpenAI’s GPTBot, Anthropic’s ClaudeBot, Google’s Google-Extended, Perplexity’s PerplexityBot, Apple’s Applebot-Extended, and others) each control whether your content can be used to train their AI models or be cited in their AI-mediated answers. The robots.txt directives that govern these crawlers are similar to the classic crawler-control patterns but distinct enough to be worth auditing deliberately. And the decision about which AI crawlers to allow versus block is a strategic question that doesn’t have a single right answer: blocking AI training crawlers may protect your content from being used to train competing AI products, but it also reduces the likelihood of your content being cited in AI Overviews and similar surfaces that increasingly drive user discovery. This post covers the AI crawler landscape, the audit methodology, the robots.txt patterns, and the strategic decisions publishers face.
For broader context, our GEO pillar covers the broader generative engine optimization discipline that this crawler audit fits into, and our SEO vs GEO bridge piece covers how AI-mediated search relates to classic Google ranking.
The AI crawler landscape in 2026
The active AI crawlers worth knowing about:
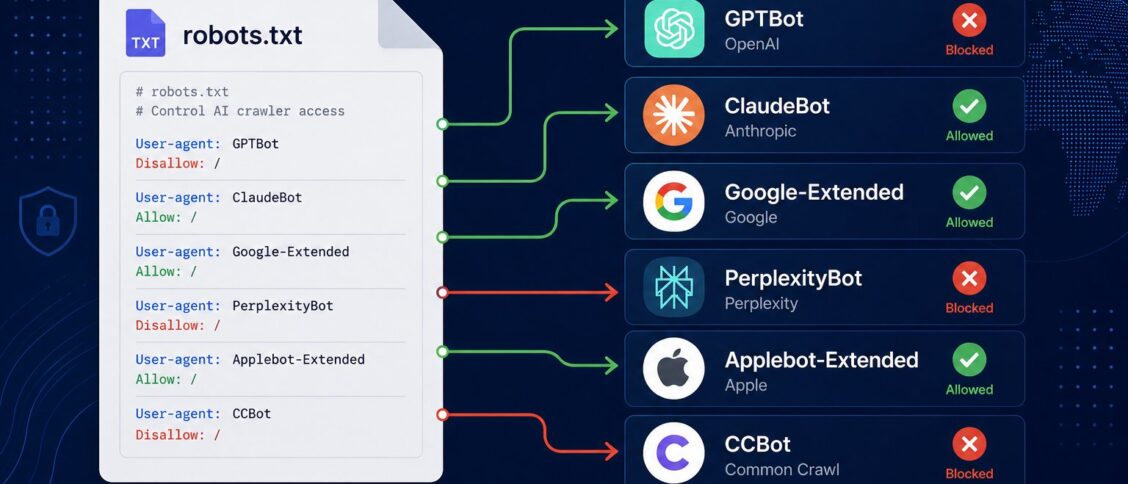
OpenAI runs three crawlers that matter. GPTBot crawls content for ChatGPT model training; OpenAI documents this and respects robots.txt directives. OAI-SearchBot crawls content for ChatGPT’s web search feature and the AI Overviews-like answer surface. ChatGPT-User is the user-agent ChatGPT uses when an active session browses the web on a user’s behalf.
Anthropic runs two crawlers. ClaudeBot crawls content for Claude model training. Claude-SearchBot (also seen as Claude-Web in some logs) crawls content for Claude’s web search and citation features.
Google runs Google-Extended as the AI-training-specific user agent that publishers can block independently of Googlebot. Importantly, Googlebot itself remains the crawler that powers Google Search results including AI Overviews; blocking Googlebot blocks everything, while blocking Google-Extended specifically blocks Google’s AI training without affecting search ranking.
Perplexity runs PerplexityBot for crawling content cited in Perplexity’s answers.
Apple runs Applebot-Extended as the AI-training-specific bot for Apple Intelligence. Applebot (without -Extended) continues to crawl for Apple’s search products including Siri.
Common Crawl runs CCBot, the long-standing open-source web crawler that produces the publicly-available Common Crawl dataset that many AI companies use for training. Blocking CCBot has indirect implications for many AI training datasets.
Other AI crawlers worth knowing about: Meta’s FacebookBot and Meta-ExternalAgent, Cohere’s cohere-ai, ByteDance’s Bytespider, and various smaller AI vendor bots. The landscape is expanding rapidly enough that new entrants appear quarterly.
Why audit AI crawler access deliberately
The audit matters for three reasons:
Strategic clarity. Most publishers haven’t made deliberate decisions about which AI crawlers to allow. The default behavior (allowing everything because nothing in robots.txt blocks AI crawlers specifically) may not match the publisher’s actual preferences. The audit forces the decision to be explicit rather than implicit.
SEO and GEO implications. Blocking the wrong crawlers can reduce visibility in AI Overviews, ChatGPT search results, Perplexity citations, and similar surfaces that increasingly drive user discovery. Allowing the wrong crawlers can expose content to training datasets the publisher would have preferred to keep out.
Verification. Robots.txt directives are advisory rather than enforced. Well-behaved AI crawlers respect the directives; less-well-behaved ones may not. Server log analysis verifies whether the crawlers are actually behaving as documented.
The audit doesn’t take long once the methodology is established. The methodology in plain language: catalog which AI crawlers exist, decide which to allow and which to block, write the robots.txt rules, deploy, then verify via server logs.
The audit methodology
Step 1: Inventory current robots.txt. Fetch your robots.txt file and examine the current state. Most sites have robots.txt rules for Googlebot, Bingbot, and a handful of common bots, but explicit rules for AI crawlers are still uncommon as of mid-2026. Note what’s currently allowed, blocked, or unspecified.
Step 2: Inventory current crawl behavior. Examine the last 30-90 days of server access logs. Filter for known AI crawler user-agents (GPTBot, ClaudeBot, Google-Extended, Applebot-Extended, PerplexityBot, CCBot, OAI-SearchBot, Claude-SearchBot, etc.). Note crawl frequency, paths crawled, and response codes returned. The pattern reveals which crawlers are actually hitting your site and how often.
Step 3: Decide your access policy. For each AI crawler, decide whether to allow, block, or partially allow access. The decision framework is covered in the next section.
Step 4: Write the robots.txt rules. Translate your decisions into robots.txt directives. The pattern is straightforward: User-agent: GPTBot followed by Disallow: / blocks GPTBot from the entire site. Allow: / permits access. Sections can apply to specific paths.
Step 5: Deploy and verify. Push the updated robots.txt. Wait 7-30 days for the crawlers to pick up the changes (most AI crawlers re-fetch robots.txt daily). Then re-examine server logs to verify compliance.
Step 6: Schedule recurring audits. AI crawlers come and go; new ones launch quarterly. Schedule a recurring audit (quarterly is reasonable for most publishers) to keep the policy current with the evolving landscape.
The whole audit takes a few hours initially and roughly an hour per recurring pass.
The decision framework
For each AI crawler, the decision framework asks:
Does allowing this crawler benefit my content discovery? AI surfaces (ChatGPT search, AI Overviews, Perplexity, Claude search) increasingly drive user clicks. Allowing the search-focused crawlers (OAI-SearchBot, Claude-SearchBot, PerplexityBot, Googlebot) generally helps content discovery. Blocking them generally hurts.
Does allowing this crawler help my brand authority in AI responses? When an AI is asked about your topic area, citations to your brand appear in answers. Crawlers that build the AI’s knowledge enable those citations. Allowing training crawlers (GPTBot, ClaudeBot, Google-Extended, Applebot-Extended) generally helps brand presence in AI responses. Blocking them generally reduces it.
Does allowing this crawler harm my content moat? If your content has substantial competitive value (proprietary research, exclusive coverage, paid content), training crawlers may incorporate it into models that compete with you. The competitive-moat concern is the main argument for blocking training crawlers.
Does allowing this crawler create legal exposure? Some publishers have specific contracts or regulatory constraints that prohibit AI training use of their content. For these publishers, blocking training crawlers is a compliance requirement rather than a strategic choice.
The right answers vary by publisher type. News publishers often block training crawlers (concern about being used to train competing AI products) while allowing search crawlers (concern about visibility loss). Marketing-focused sites often allow everything (visibility benefits outweigh the training concerns). Specialized professional publishers often allow training selectively (build authority for their topic area) while blocking general web crawlers (limit broader use).
Sample robots.txt patterns
Three illustrative policies:
Maximum AI visibility (allow everything):
# Default behavior: AI crawlers allowed
User-agent: GPTBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Applebot-Extended
Allow: /
User-agent: CCBot
Allow: /Block training, allow search (the "AI Overviews-friendly" pattern most publishers might prefer in 2026):
# Block AI training crawlers
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
# Allow AI search and citation crawlers
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
# Googlebot for AI Overviews and regular search
User-agent: Googlebot
Allow: /Block everything AI (the "competitive moat" pattern):
User-agent: GPTBot
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-SearchBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
# Googlebot still allowed for classic search
User-agent: Googlebot
Allow: /For most publishers, the middle pattern (block training, allow search) balances brand visibility against competitive moat reasonably well. The decision is still publisher-specific and worth thinking through deliberately.
Verifying compliance via server logs
After deploying robots.txt changes, server log analysis verifies whether the AI crawlers are actually respecting the directives. The pattern:
Filter recent access logs for the AI crawler user-agents you set rules for. For each crawler, count the number of requests in the period after the robots.txt change took effect. Compare against the baseline before the change.
Compliant crawlers show meaningful drops in requests to disallowed paths within 7-30 days of the robots.txt update. GPTBot, ClaudeBot, Google-Extended, and PerplexityBot generally comply within this window.
Less compliant crawlers may continue accessing disallowed paths or access at lower frequencies but not zero. CCBot occasionally shows partial compliance because its respect for robots.txt depends on how the underlying Common Crawl process handles updates.
Bots claiming to be AI crawlers but using non-standard user-agents may be unrelated bots that happen to identify themselves with AI-adjacent labels. Verify via IP address against the AI vendor’s published IP ranges where available.
For publishers concerned about non-compliant access, technical mitigations beyond robots.txt include Cloudflare’s AI bot blocking features, custom web application firewall rules, and IP-based blocking against known AI vendor ranges.
What this means strategically
The deeper takeaway is that AI crawler access policy is now a real content strategy dimension that publishers need to manage deliberately. The "allow everything by default" approach was reasonable in 2023; in 2026 it’s a missed opportunity at minimum and a competitive risk for some publisher types. The audit takes a few hours, the policy decision is straightforward once framed, and the ongoing maintenance is light. The cost of getting it wrong (lost AI visibility, unintended training use, competitive exposure) substantially exceeds the cost of running the audit.
Frequently Asked Questions
What is an AI crawler?
An AI crawler is a bot operated by an AI vendor that crawls web content for one of two purposes: training the vendor’s AI models or supporting the vendor’s AI-mediated search and answer features. Training crawlers (GPTBot, ClaudeBot, Google-Extended, Applebot-Extended, CCBot) build the underlying datasets that train models. Search crawlers (OAI-SearchBot, Claude-SearchBot, PerplexityBot, ChatGPT-User) crawl content to power AI-generated answers that cite source URLs. Some bots serve both purposes.
Should I block AI training crawlers?
The decision depends on publisher type. News publishers and content publishers with substantial competitive moats often block training crawlers to prevent their content from being incorporated into models that may compete with them. Marketing-focused sites and brand-building content often allow training crawlers to build presence in AI vendor responses. The middle pattern (block training, allow search) works well for many publishers who want AI visibility without contributing to training datasets.
How do I see which AI crawlers are hitting my site?
Server access log analysis. Filter recent logs for known AI crawler user-agents (GPTBot, ClaudeBot, Google-Extended, Applebot-Extended, OAI-SearchBot, Claude-SearchBot, ChatGPT-User, PerplexityBot, CCBot, and others). Count requests per crawler over the past 30-90 days. The pattern shows which AI crawlers are actively crawling your content and how frequently. Most web analytics platforms can produce this report with appropriate filtering.
What’s the difference between Googlebot and Google-Extended?
Googlebot is Google’s main search crawler that powers Google Search results, including AI Overviews. Blocking Googlebot blocks Google Search visibility entirely. Google-Extended is Google’s AI-training-specific user-agent that can be blocked independently. Blocking Google-Extended prevents Google from using your content for AI model training without affecting Google Search ranking or AI Overviews citation. The two are deliberately separable.
Do AI crawlers actually respect robots.txt?
The well-behaved AI vendors (OpenAI, Anthropic, Google, Perplexity, Apple) document their crawler user-agents and respect robots.txt directives. Their public crawler documentation explicitly commits to respecting Disallow rules. Server log analysis generally shows compliance within 7-30 days of robots.txt changes. Less well-behaved bots may not comply; technical mitigations beyond robots.txt (Cloudflare AI bot blocking, web application firewall rules, IP-based blocking) handle that case for publishers who need stronger enforcement.
How often should I audit AI crawler access?
Quarterly is reasonable for most publishers. The AI crawler landscape changes quickly (new bots launch, existing bots change user-agents, vendor policies shift), and recurring audits keep your access policy current. Each audit takes about an hour after the initial methodology is established. For publishers in fast-moving industries or with substantial AI-relevant content, monthly audits may be appropriate.
What happens to AI Overviews citations if I block training crawlers?
Blocking AI training crawlers (Google-Extended, GPTBot, ClaudeBot) generally reduces but doesn’t eliminate citation probability. AI surfaces increasingly use real-time web search for answers (the OAI-SearchBot, Claude-SearchBot, Googlebot patterns), and content reachable via those crawlers can still be cited even if it wasn’t used for training. For publishers who want maximum AI Overviews visibility, allowing the search-focused crawlers (and Googlebot specifically) is the higher-leverage action than allowing training crawlers.
Are there legal implications to allowing AI training crawlers?
Depends on the content type and the publisher’s contracts. Original journalism, proprietary research, and licensed content may have contractual restrictions on AI training use. Several lawsuits in 2024-2025 raised legal questions about whether AI training on copyrighted content constitutes fair use. Publishers in regulated industries or with substantial content licensing should consult counsel about their specific AI training policy. The robots.txt audit is independent of these legal questions but informs the practical implementation of whatever policy is chosen.