Supabase is an open-source backend-as-a-service (BaaS) platform built on PostgreSQL. Founded in 2020 by Paul Copplestone and Ant Wilson, Supabase reached a $10.5 billion valuation in early June 2026 after raising $500 million in a Series F that doubled the company’s value in eight months, driven primarily by AI coding agents (Claude Code most prominently) that now deploy the majority of new databases on the platform. If that sounds like a lot of context for a "what is Supabase" lead, it’s because the Supabase story has changed substantially in the last 12 months: what was widely described in 2024 as "the open-source Firebase alternative" is now better described as the default backend infrastructure for AI-era applications, with vibe-coded apps, agent-deployed databases, and AI inference workloads making up the bulk of new platform usage.
The technical positioning is simpler than the strategic positioning. Supabase gives you a Postgres database, an authentication system, file storage, real-time subscriptions, serverless edge functions, and a built-in vector database for AI workloads, all wired together under a single API. You don’t build the auth tables yourself, you don’t write the realtime websocket layer, you don’t deploy a separate vector database for embeddings. The platform handles the plumbing and you focus on application logic. The difference from Firebase, AWS Amplify, and other BaaS competitors is that the underlying database is real Postgres rather than a proprietary NoSQL store, which means your data, schemas, and queries are portable in a way they aren’t on competing platforms.
This post covers what Supabase actually is, the architectural choices that distinguish it from Firebase and other BaaS platforms, the six core services (Database, Auth, Storage, Realtime, Edge Functions, Vector), the pricing tiers, the strategic context including the June 2026 funding round and the Multigres preview, where Supabase fits in modern application stacks, the limitations worth knowing before you commit, and the practical decisions teams should make today.
What Supabase actually is
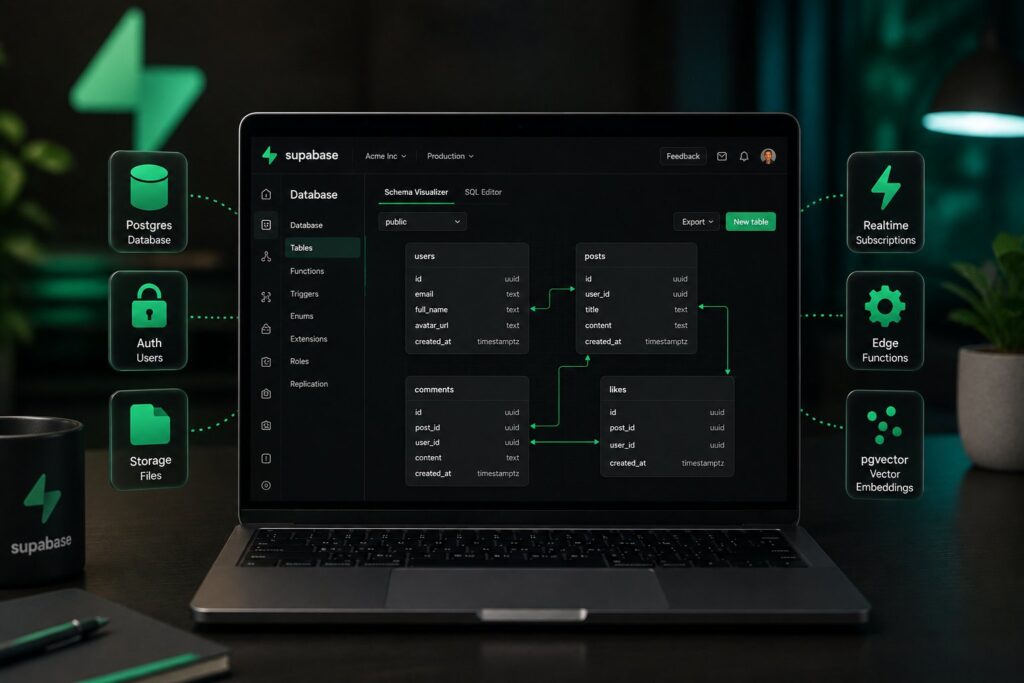
Supabase is a unified backend platform that gives you the services most web and mobile applications need (a database, user authentication, file storage, real-time updates, server-side functions, vector embeddings) without making you operate the infrastructure underneath. You sign up, create a project, and within about thirty seconds you have a working Postgres database, a REST API, a realtime websocket endpoint, and an admin dashboard.
The core architectural choice that defines Supabase: the underlying database is real PostgreSQL, exposed directly to your application via APIs that Supabase generates automatically from your schema. When you create a table in the Supabase dashboard, the platform generates the REST endpoints, the GraphQL endpoints, the realtime subscription paths, and the type-safe client SDK bindings for that table. The platform layer sits on top of a database you can also connect to with any standard Postgres client (psql, DBeaver, your ORM, your migrations tool), and the SQL you write is real Postgres SQL.
That sounds like a small technical detail but it’s the headline feature in practice. With Firebase (Google’s competing BaaS), the database is Firestore or the legacy Realtime Database, both proprietary NoSQL stores. Your data lives in Google’s format, your queries use Google’s API, and migrating away from Firebase means rewriting your data layer. With Supabase, the database is open-source Postgres. The data is yours, the schemas are standard, and a migration to a self-hosted Postgres or a competing Postgres-backed BaaS (Neon, Crunchy Data, anything) is a pg_dump away.
Supabase is also open source. The platform itself runs as a collection of open-source services under the Apache 2.0 license, and you can self-host the entire stack on your own infrastructure if you prefer. Most teams use the managed cloud (Supabase Cloud) because operating Postgres in production is genuinely hard work, but the self-host path exists and is officially supported. That’s another sharp contrast with Firebase, which is impossible to self-host.
For broader infrastructure context, our What Is Vercel? pillar covers the frontend-cloud-platform side of the modern stack (where Vercel often pairs with Supabase as the backend layer), and our vector databases primer covers the embedding-database concepts that Supabase’s pgvector integration uses.
The six core services
Supabase organizes its capabilities into six services, each accessible through the same unified API and dashboard:
Database (Postgres). A managed Postgres instance with auto-generated REST and GraphQL APIs, real-time subscriptions, row-level security (RLS) for fine-grained access control, and a visual schema editor that ships with the dashboard. The database is your single source of truth; every other service is grounded in it. Postgres extensions are first-class citizens, with pgvector, PostGIS, pg_cron, pg_net, and dozens of others available out of the box.
Auth. Email/password sign-in, social logins (Google, GitHub, Apple, Discord, dozens more), magic links, passkeys (added in 2026), phone-number OTP, anonymous sign-in, and multi-factor authentication. The auth system is integrated with the database at the row level: row-level security policies can reference the authenticated user’s ID, role, or any custom claim, so authorization logic lives in the database rather than scattered across application code.
Storage. S3-compatible object storage for user-uploaded files (avatars, attachments, media). Storage policies use the same RLS engine as the database, so file access rules are written in SQL and applied automatically. Supabase’s storage tier handles image transformations (resize, crop, format conversion) at the edge, which removes the need for a separate image-processing pipeline for most apps.
Realtime. WebSocket-based real-time subscriptions to database changes. Subscribe to "all updates to the messages table for room X" and your client receives events as they happen, with the auth and RLS layers automatically scoping what each client sees. Realtime also supports broadcast channels (low-latency pub/sub for client-to-client messaging) and presence (who’s online in a given context).
Edge Functions. TypeScript serverless functions that run on Deno at the edge, close to your users globally. Edge Functions are how you handle webhooks, integrate with third-party APIs, send emails, run cron jobs, and put server-side logic into your stack. The runtime supports the standard Web APIs (fetch, Request, Response, ReadableStream) and has direct access to your Supabase database via the auto-generated client.
Vector (pgvector). Built-in vector embeddings via the pgvector Postgres extension. Store embeddings as columns in your tables, query by similarity using cosine distance or inner product, and combine vector search with traditional SQL filters in a single query. pgvector ships free on every Supabase plan, which is unusual: most platforms either charge separately for vector capabilities or require a dedicated vector database. For AI applications (RAG pipelines, semantic search, embedding-based recommendations), this matters because it removes a whole infrastructure layer.
The six services share a single API surface, a single dashboard, a single billing context, and a single set of permissions. That’s the practical benefit of a unified BaaS: you’re not stitching together a database vendor, an auth vendor, a storage vendor, a realtime vendor, a serverless vendor, and a vector database vendor. You’re configuring one platform that handles all six.
Why the AI coding agent story matters
The single most consequential change in Supabase’s 2024-to-2026 trajectory is the rise of AI coding agents as the primary deployment driver. Per Supabase’s own announcements around the June 2026 Series F, AI coding agents (especially Claude Code) now deploy the majority of new databases on the platform, with database growth running 600% year-over-year and the user base more than doubling since the Series E in November 2025.
This matters for two reasons.
The first is technical. AI coding agents need a backend that can be provisioned programmatically, configured via API or CLI, and reasoned about by a model that doesn’t have a human’s full context about a project. Supabase’s combination of a known database technology (Postgres, which models know well from training data), a clean API surface (REST/GraphQL auto-generated from schema), a sensible default security model (RLS), and predictable pricing makes it agent-friendly in a way that platforms with proprietary APIs or non-standard data models aren’t. When Claude Code asks itself "what backend should I use for this vibe-coded application," Supabase is increasingly the answer because the model has high confidence in the integration patterns.
The second is strategic. The vibe-coding boom (the trend of users describing apps in natural language and letting AI agents build them) is the largest category of new application development in 2026. If Supabase is the default backend for that category, the company captures a structurally large share of the new application market. The June 2026 raise was explicitly framed by Supabase as funding to "accelerate the lead in agentic infrastructure," which is a positioning statement: Supabase isn’t just a BaaS, it’s the BaaS that AI agents prefer.
For builders, the implication is practical. If your team is building with AI assistance (which most teams are in 2026), the backend platform that AI agents understand and integrate with cleanly will save substantial time over platforms that require human-led integration work. That’s a real productivity argument, not just a marketing one.
Our Claude Code vs OpenAI Codex comparison covers the agent landscape that’s driving this trend, and our AI agents pillar covers the broader category.
Pricing tiers
Supabase pricing in 2026:
Free. $0. Two projects, 500 MB database storage, 50,000 monthly active users (MAU), 200 concurrent realtime connections, 1 GB file storage. Projects pause after 7 days of inactivity to control free-tier costs. Excellent for prototypes, side projects, and proof-of-concept work.
Pro. $25/month per project plus usage-based fees. Includes 8 GB database storage, 100K MAU, 100 GB file storage, 500 concurrent realtime connections, and $10/month in compute credits (which covers one Micro instance or offsets the cost of any larger instance). Daily backups for 7 days. No project pausing.
Team. $599/month. Includes Pro features plus SOC2 Type 2 and ISO 27001 compliance, 14-day backup retention, priority support, SSO for the team dashboard, and the ability to apply organization-level policies across multiple projects. This is the right tier for production teams shipping commercial applications.
Enterprise. Custom pricing. Adds HIPAA compliance, dedicated support, custom backup retention, BYO cloud deployment (Supabase running inside your AWS/GCP/Azure account), and the contract terms regulated industries require.
The pricing model is consistent with the broader trend toward usage-based billing in developer infrastructure: most teams pay the base subscription fee plus metered overages for the resources they actually consume. The compute add-on for Pro ($10/month in credits) is meaningfully generous compared to competing platforms.
For practical cost planning, the Pro tier ($25/month base) covers most small commercial applications without much overage. The jump to Team ($599/month) is significant and primarily justified by the compliance certifications, not the resource limits. Many teams stay on Pro until they need SOC2/ISO 27001 for an enterprise customer or until they’re operating multiple production projects under shared governance.
The Multigres preview
A specific 2026 release worth noting: Supabase shipped a preview of Multigres, an open-source horizontal scaling layer for Postgres that brings sharding, zero-downtime migrations, and high availability to the standard Postgres deployment story.
Postgres’ biggest historical weakness compared to NoSQL databases like Firestore or DynamoDB has been horizontal scalability. Postgres scales vertically (you make the server bigger) well, but sharding (splitting data across multiple Postgres instances) has traditionally required application-level work and operational complexity. Multigres addresses that by giving Postgres deployments a sharding layer that’s automatic and transparent to the application.
For most Supabase users, Multigres won’t matter immediately. Single-instance Postgres handles applications well into the tens of thousands of concurrent users with proper configuration. But for the long tail of applications that outgrow vertical scaling, Multigres is the path that keeps you on Postgres rather than forcing a migration to a sharded NoSQL store. The strategic implication: Supabase is removing the single legitimate reason to choose Firestore over Postgres for new applications, which is the long-term scale story.
Multigres is in preview as of mid-2026 and isn’t yet a production deployment target for most teams. Watch for GA later in 2026 or early 2027.
Limitations worth knowing
Supabase has genuine limitations worth understanding before you commit:
Postgres is your single point of complexity. Everything on the platform depends on the underlying Postgres database. If you don’t know how to administer Postgres at some level (indexes, query plans, vacuuming, role management), you’ll eventually hit operational issues you can’t debug without learning. This isn’t a Supabase problem (it’s a Postgres reality), but it’s a real prerequisite that NoSQL platforms paper over.
Vendor lock-in is real even with open data. Yes, your data is portable. But your auth integration, your RLS policies, your edge functions, your realtime subscriptions, your storage policies, all of those are written against Supabase’s APIs. Migrating to a competing Postgres-backed BaaS requires rewriting the platform integration, even if the database itself moves cleanly. Self-hosting Supabase eliminates this concern but introduces operational work.
Edge Functions are Deno, not Node. If your team is heavily Node.js-oriented, the Deno runtime difference will matter. Most npm packages work, but the runtime semantics differ in subtle ways and the debugging story is less mature.
Realtime has scaling constraints. The 500-concurrent-connection limit on the Pro plan is real, and even on higher tiers, real-time at high scale requires careful design. For applications that need tens of thousands of concurrent realtime subscribers, Supabase’s realtime tier may not be the right primitive.
Vector search is good but not class-leading. pgvector is excellent for most embedding workloads and free on all plans. For very large vector indexes (hundreds of millions of vectors) or very high query throughput, dedicated vector databases (Pinecone, Weaviate, Qdrant) still outperform. The pgvector trade-off is "good enough for most things, in the same database as the rest of your data" vs "best-in-class, separate infrastructure."
Pricing predictability is good but not bulletproof. The base subscription is predictable; the usage overages can surprise teams that don’t monitor consumption. Build cost monitoring into your operational dashboards from day one if your application is growing fast.
Where Supabase fits in modern stacks
The dominant 2026 web application stack pairs Supabase with a frontend framework (Next.js, SvelteKit, Astro, Nuxt, Remix) deployed on a frontend cloud platform (Vercel, Netlify, Cloudflare Pages). The pattern: Supabase handles the backend services, the frontend framework handles the UI and SSR layer, the frontend platform handles deployment and edge delivery.
For mobile applications, Supabase pairs with React Native, Flutter, or Swift/Kotlin native development. The auth and database SDKs are mature across all major mobile frameworks.
For AI applications specifically, Supabase pairs with the LLM providers (OpenAI, Anthropic, Google) for inference, with pgvector handling embeddings on the Supabase side. The integration patterns are well-documented and Supabase’s Model Context Protocol support makes it usable by AI agents as a tool surface.
For desktop or server-rendered applications, Supabase works with any standard Postgres client. The auth and storage layers are accessible via REST APIs from any HTTP client, so the platform isn’t locked to JavaScript or any specific runtime.
The combinations that work well in 2026:
- Next.js + Vercel + Supabase for SaaS and content-driven applications
- SvelteKit + Cloudflare + Supabase for performance-sensitive applications
- React Native + Expo + Supabase for mobile apps
- Astro + Vercel + Supabase for content-heavy sites with light interactivity
- Any framework + Supabase + Claude Code/Cursor for agent-assisted development
What teams evaluating Supabase should do
Six practical actions:
- Start on the free tier. Provision a project, create a few tables in the schema editor, query them from a client of your choice. The free tier is genuinely usable for evaluation; you can model your real schema and run real queries to assess fit.
- Read the row-level security documentation. RLS is the Supabase mental model for authorization, and the platform’s security story depends on you using it correctly. If your team isn’t comfortable with the RLS pattern after reading the docs, that’s a meaningful signal about whether Supabase is the right fit.
- Plan the migration story before you commit. Supabase’s data portability is real, but the platform integrations are sticky. If your team has a hard requirement to keep migration optionality high (regulated industry, multi-vendor strategy, anti-lock-in policy), self-hosting Supabase is the most defensible path.
- Test the realtime layer against your expected concurrent-subscriber count. The Pro tier’s 500-connection limit is the most common surprise. If your application needs thousands of concurrent realtime subscribers, model the cost on the higher tiers before committing.
- Validate the pgvector workflow against your AI workload. If you’re building an AI application, the embedding-and-search workflow on pgvector is the path you’ll use most. Run a representative workload (a few hundred thousand vectors at minimum) and measure query latency and accuracy against your requirements.
- Set up cost monitoring before you go to production. Usage-based pricing rewards teams that monitor consumption and punishes teams that don’t. Build a dashboard, set budget alerts, and review monthly invoices for the first six months.
The deeper takeaway is that Supabase has become the default Postgres-backed BaaS in 2026 and the default backend for AI-era application development. For teams starting new projects, the question isn’t really "should we use Supabase" but "which Supabase tier and which migration story do we plan for." For teams operating existing applications on Firebase or another competing BaaS, the question is whether the lock-in cost of staying outweighs the migration cost of moving to Supabase, and in 2026, the math increasingly favors moving.
Frequently Asked Questions
What is Supabase?
Supabase is an open-source backend-as-a-service platform built on PostgreSQL. It provides a managed Postgres database, authentication, file storage, real-time subscriptions, serverless edge functions, and a built-in vector database (pgvector) for AI workloads, all accessible through a unified API and dashboard. Founded in 2020 by Paul Copplestone and Ant Wilson, Supabase was widely described as “the open-source Firebase alternative” before becoming the default backend for AI-era application development in 2026, reaching a $10.5 billion valuation in early June 2026 on the back of agent-driven growth.
How is Supabase different from Firebase?
The headline difference is the underlying database: Supabase uses PostgreSQL (open-source, relational, standard SQL), while Firebase uses Firestore or the legacy Realtime Database (proprietary NoSQL). That choice has cascading consequences. With Supabase, your data is portable and migratable; with Firebase, the data lives in Google’s format and migration means rewriting the data layer. Supabase is open source and self-hostable; Firebase is closed and cloud-only. Supabase exposes a relational data model with joins and transactions; Firebase requires denormalized data structures. For most modern applications, Postgres’ relational model fits better than Firestore’s document model, and the AI agent ecosystem has standardized on Postgres conventions.
Is Supabase actually open source?
Yes. The Supabase platform is licensed under Apache 2.0 and the entire stack can be self-hosted on your own infrastructure (AWS, GCP, Azure, bare metal, your laptop). Most teams use Supabase Cloud (the managed offering) because operating Postgres in production is genuine work, but the self-host path is officially supported and used by some organizations that need full data sovereignty or have compliance constraints that make managed BaaS difficult.
What does Supabase cost?
Four tiers as of 2026. Free ($0): two projects, 500 MB database, 50K MAU, projects pause after 7 days of inactivity. Pro ($25/month per project + usage): 8 GB database, 100K MAU, 100 GB storage, $10/month compute credits, daily backups. Team ($599/month): adds SOC2 Type 2 and ISO 27001 compliance, 14-day backup retention, priority support, SSO. Enterprise (custom): adds HIPAA, dedicated support, BYO cloud deployment. Usage overages apply across all paid tiers for resources beyond the included limits.
Does Supabase work well with AI agents?
Yes, and that’s the central 2026 story. AI coding agents (especially Claude Code) deploy the majority of new databases on Supabase as of mid-2026, per Supabase’s own data. The platform is agent-friendly because Postgres is a well-understood database technology in model training data, the auto-generated REST/GraphQL APIs are predictable, the row-level security pattern is reasonable for AI-deployed applications, and the pricing is predictable enough for agents to make informed decisions. Supabase’s June 2026 Series F was framed explicitly as funding to “accelerate the lead in agentic infrastructure.”
What is pgvector and why does it matter?
pgvector is the Postgres extension that adds vector embedding storage and similarity search to Postgres. With pgvector, you store embeddings as columns alongside your other data and query by similarity (cosine distance, inner product, L2 distance) in the same SQL queries you use for everything else. Supabase ships pgvector free on every plan, including the free tier. For AI applications (RAG pipelines, semantic search, embedding-based recommendations), this removes the need for a separate vector database vendor and lets you keep embeddings in the same database as the rest of your application data.
What is Multigres?
Multigres is Supabase’s preview release of an open-source horizontal scaling layer for Postgres that brings sharding, zero-downtime migrations, and high availability to standard Postgres deployments. The strategic motivation: Postgres’ historical weakness against NoSQL stores has been horizontal scalability, and Multigres removes that as a reason to choose Firestore or DynamoDB over Postgres for new applications. Multigres is in preview as of mid-2026 with GA expected later in 2026 or early 2027. Most Supabase users won’t need Multigres immediately, but its existence changes the long-term scaling story for the platform.
Should I migrate from Firebase to Supabase?
The lock-in cost of staying on Firebase compounds over time, and the migration cost of moving to Supabase compounds with application complexity. For small Firebase applications (a few collections, modest user count, no heavy realtime usage), the migration is meaningfully smaller than most teams expect: model the data in Postgres, write the migration scripts, update the client SDK, deploy. For larger applications (substantial Firestore queries, complex security rules, heavy realtime usage), plan for several weeks of work and budget for the integration rewrite. The economic argument for moving has strengthened in 2026 as Supabase has reached scale and the AI tooling ecosystem has standardized on Postgres conventions; the inertia argument for staying has weakened correspondingly.


